
题目介绍
题目:爬取2017年1月1日到如今,github上,最流行的20个(100个?)大数据相关的项目。要求:请自定义/量化“最流行”
需求分析
爬取项目为github上开源项目
要求
- 时间为2017年1月1日至今项目
- 自定义爬取个数(20个)
- 自定义爬取内容(大数据相关)
- 自定义项目排序(最流行、复刻/克隆次数对多、最近发布等)
项目流程
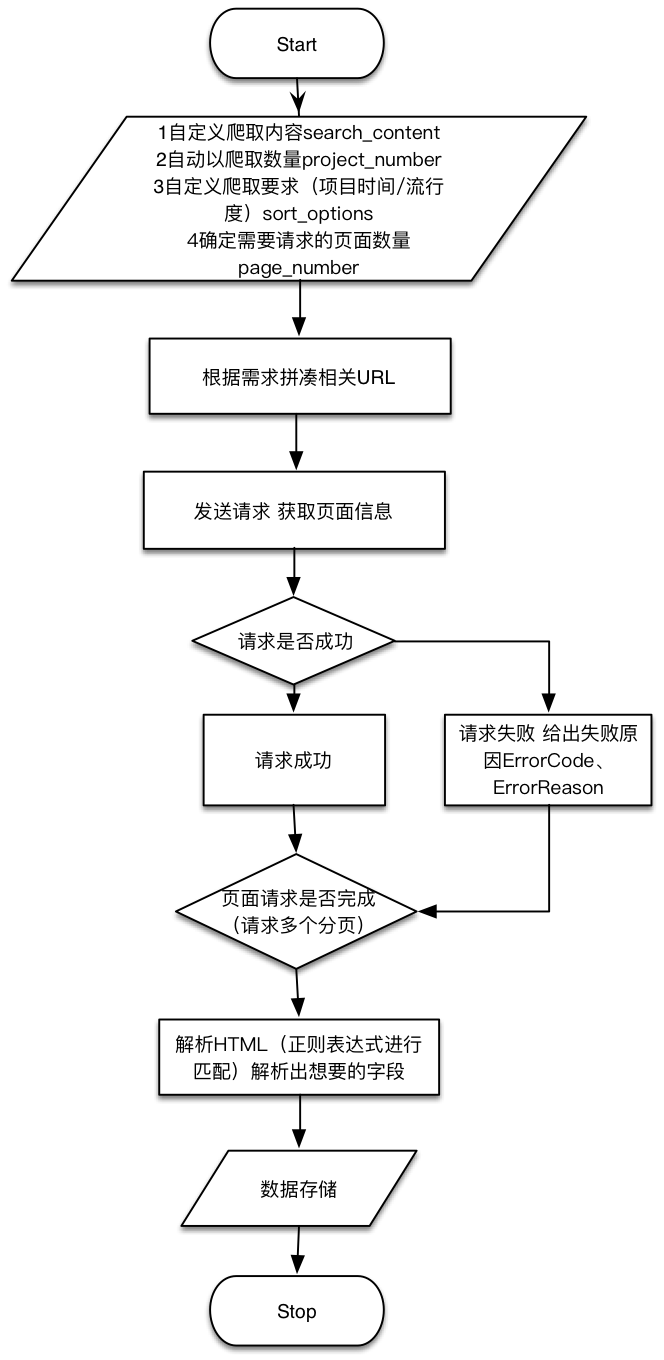
从github上爬取处理的流程大致为:根据定义的量化信息爬取页面、解析html页面取到相关内容信息、进行内容存储。
爬虫流程图
代码设计
编写爬虫类,量化信息可作为变量输入
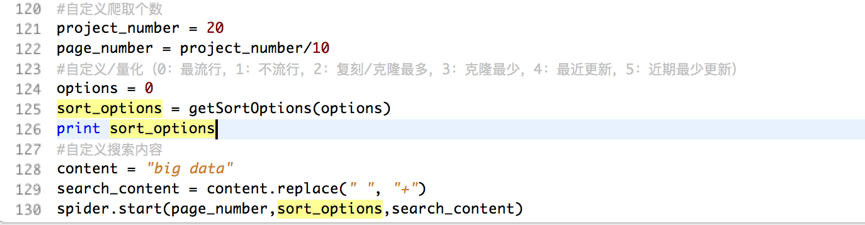
发送URL请求,获取页面方法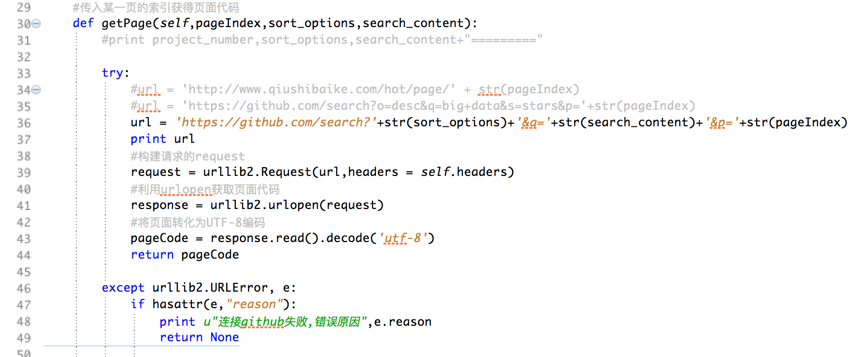
解析页面HTML方法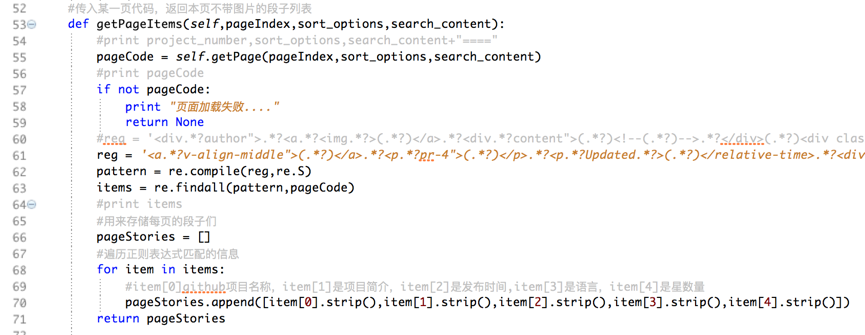
内容存储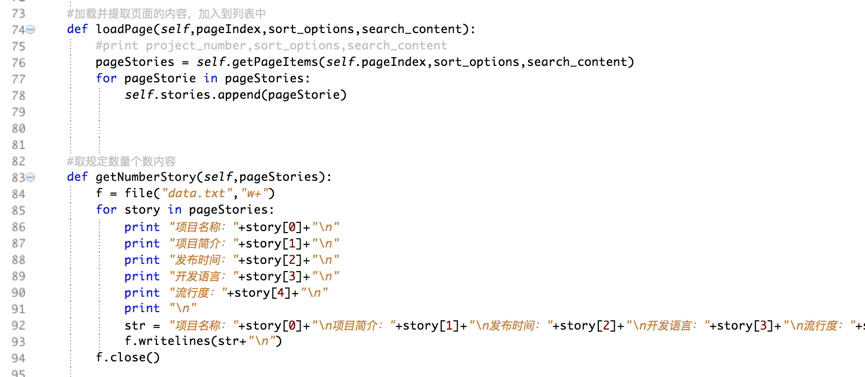
完整代码
|
|
问题
Github做了反爬虫机制,如果定义的爬取项目数量较多,需要请求多个页面,由于URL请求次数过多,Github会返回由于多次请求错误。准备下一版做一个反爬虫机制来解决。


