
一、简介
1.Spark介绍
Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark,是一种”One Stack to rule them all”的大数据计算框架,期望使用一个技术完美的解决大数据领域的各项计算任务。Apache官方对Spark的定义:通用的大数据快速处理引擎。Spark除了一站式的特点之外,另外一个最重要的特点就是基于内存进行计算,从而让它的速度可以达到MapReduce、Hive的数倍甚至数十倍。
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松地操作分布式数据集(Scala 提供一个称为 Actor 的并行模型,其中Actor通过它的收件箱来发送和接收非同步信息而不是共享数据,该方式被称为:Shared Nothing 模型)。在Spark官网上介绍,它具有运行速度快、易用性好、通用性强和随处运行等特点。
现在已经有很多大公司正在生产环境下深度地使用Spark作为大数据的计算框架,包括eBay、Yahoo!、BAT、网易、京东、华为、大众点评、优酷土豆、搜狗等。Spark也获得了多个世界顶级的IT厂商的支持,包括IBM、Intel等。
2.Spark特点
速度快:Spark基于内存进行计算(随着数据量的增大,也有部分计算基于磁盘,如shuffle)。易用性好:Spark是基于RDD的计算模型,比Hadoop的基于MapReduce的计算模型更加易于理解和上手开发,实现各种复杂功能,比如二次排序、topn等复杂操作时,更加便捷。Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。通用性强:Spark提供了Spark RDD、Spark SQL、Spark Streaming、MLlib、GraphX等技术组件,可以一站式的完成数据领域的离线批处理、交互式查询、实时流计算、机器学习与图计算等重要的任务和问题。集成Hadoop:Spark并不是要成为一个大数据领域的”独裁者”,一个人霸占大数据领域的所有”地盘”,而是与Hadoop进行了高度的集成,两者可以完美的配合使用。Hadoop的HDFS、Hive、HBase负责存储,YARN负责资源调度;Spark负责大数据计算。实际上Hadoop+Spark的组合,是一种”double win”的组合。
3.Spark适用场景
目前大数据处理场景有以下几个类型:
- 复杂的批量处理(Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时;
- 基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分钟之间
- 基于实时数据流的数据处理(Streaming Data Processing),通常在数百毫秒到数秒之间
目前对以上三种场景需求都有比较成熟的处理框架:
- 第一种情况可以用Hadoop的MapReduce来进行批量海量数据处理。
- 第二种情况可以Impala进行交互式查询。
- 第三种情况可以用Storm分布式处理框架处理实时流式数据。
以上三者都是比较独立,各自一套维护成本比较高,而Spark的出现能够一站式平台满意以上需求。
通过以上分析,总结Spark场景有以下几个:
- Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小
- 由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合数据量不是特别大,但是要求实时统计分析需求
二、Spark安装部署
1.Scala安装
在这里我提前将Scala安装包下载好了并且传到了我的master机器上,可登录Scala官方网站下载,如果hadoop集群中可以连接外网,同样可以通过wget的方式获得,如下:
wget http://downloads.lightbend.com/scala/2.12.0/scala-2.12.0.tgz
这里获得的是目前的最新版本。如果系统提示没有找到wget命令,可以通过yum install wget进行安装。
(1).Scala解压安装
root用户操作,进入下载好的scala-2.12.0.tgz目录
mv scala-2.12.0.tgz /usr
注意: 这里我将其权限修改为root用户拥有,也就是说root级的权限,当在root用户里进行source 配置文件时,在hadoop用户层级却不能使用,需要将配置文件配置好后,在hadoop用户中也进行source /etc/profile,这样scala便作为一个系统级工具可以任意调用。这里最好建一个软链,后期更新版本只需要更改软链的指向即可,不需要更改环境变量里的配置
tar zxvf scala-2.12.0.tgz
chown -R root:root scala-2.12.0
ln -s scala-2.12.0 scala
(2).环境变量配置
vi /etc/profile
#在后边添加
#set scala environment
export SCALA_HOME=/usr/scala
export PATH=\$PATH:\$SCALA_HOME/bin
保存退出:wq
source /etc/profile
(3).将Scala复制到其他节点
scp -r /usr/scala-2.12.0 root@Slave1.Hadoop:/usr
scp -r /usr/scala-2.12.0 root@Slave2.Hadoop:/usr
并登录到其他slave节点,设置软链
ln -s /usr/scala-2.12.0 scala
(4).验证Scala
在命令行中输入
scala -version
可以看到出现Scala的相关版本信息,则配置成功。
Scala code runner version 2.12.0 – Copyright 2002-2016, LAMP/EPFL and Lightbend, Inc.
2.Spark安装
由于Spark是基于Scala开发的,故相关的版本需要与Scala相关的版本对应,在Spark下载页选择不同的Spark版本可以看到相关的Scala版本要求,由于我们装的Hadoop为2.7.1版本,而2.7版本以上可以安装Spark2.0以上,因此下载对应的最新版本spark-2.0.2-bin-hadoop2.7.tgz。将下载好的spark包拷贝到Master相关的目录下,这里还是scp到/usr/local/src下。
(1).Spark解压安装
root用户登录
cd /usr/local/src && ls
cp spark-2.0.2-bin-hadoop2.7.tgz /usr
cd /usr
tar xf spark-2.0.2-bin-hadoop2.7.tgz
mv spark-2.0.2-bin-hadoop2.7 spark
chown -R hadoop:hadoop spark
rm spark-2.0.2-bin-hadoop2.7.tgz
(2).Spark配置
配置log4j.properties
cd /usr/spark/conf
cp log4j.properties.template log4j.properties
vi log4j.properties
修改 log4j.rootCategory=WARN, console
配置spark-env.sh
cd /usr/spark/conf
mv spark-env.sh.template spark-env.sh
vi spark-env.sh
在后边添加
export JAVA_HOME=/usr/java/jdk1.8.0_111
export HADOOP_CONF_DIR=/usr/hadoop/etc/hadoop #hadoop配置文件的路径
export SPARK_MASTER_HOST=Master.Hadoop #spark的master主机名
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=512M
保存退出:wq
配置slaves
mv slaves.template slaves
vi slaves
删除localhost,添加slave节点hostname
Slave1.Hadoop
Slave2.Hadoop
保存退出:wq
(3).添加到环境变量
#set spark environment
export SPARK_HOME=/usr/spark
export PATH=$PATH:$SPARK_HOME/bin #注意这里只添加了bin的路径,没有添加sbin,因为spark的启动命令和hadoop启动命令一样,所以如果都添加便难以区分。
(4).复制到其他节点
scp -r /usr/spark root@Slave1.Hadoop:/usr
scp -r /usr/spark root@Slave2.Hadoop:/usr
将配置文件复制到其他slave节点
scp /etc/profile root@Slave1.Hadoop:/usr
scp /etc/profile root@Slave2.Hadoop:/usr
同样需在所有的节点中让配置文件生效
source /etc/profile
分别在所有节点的hadoop和root用户中source /etc/profile,环境变量更新让其生效
(5).启动验证
#启动(由于和hadoop的启动shell名字一样,需要注意)
cd /usr/spark/sbin
./start-all.sh
会看到如下结果:
[hadoop@Master sbin]$ ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/spark/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-Master.Hadoop.out
Slave2.Hadoop: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-Slave2.Hadoop.out
Slave1.Hadoop: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-Slave1.Hadoop.out
jps查看进程会发现master上多出Master进程,在slave上会多出Worker进程。则表示spark安装启动成功。
#可以通过物理机在浏览器中查看集群状态
http://10.211.55.13:8080/
如图所示: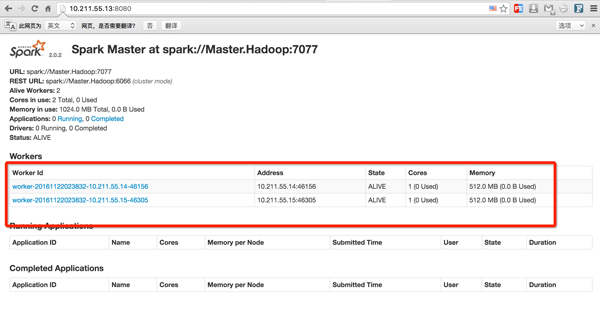
#命令行交互验证
./bin/spark-shell
scala> val textFile = sc.textFile(“file:////usr/spark/README.md”)
textFile: org.apache.spark.rdd.RDD[String] = file:////usr/spark/README.md MapPartitionsRDD[1] at textFile at:24
scala> textFile.count()
res0: Long = 99
scala> textFile.first()
res1: String = # Apache Spark
:q或者:quit 可推出Scala
至此,spark安装配置成功,接下来安装storm。


