
1.部署环境及相关版本软件
- 操作系统:MAC OS X EI Caption 10.11.6
- CPU:2.7 GHz Intel Core i5
- 内存:8 GB 1867 MHz DDR3
- 虚拟机:Parallels Desktop 10
- 操作系统:CentOS-7-x86_64-DVD-1511.ISO
- JDK:jdk-8u111-linux-x64.tar.gz
- 其他软件:
hadoop-2.7.1.tar.gz hbase-1.1.7-bin.tar.gz apache-hive-1.2.1-bin.tar.gz zookeeper-3.4.6.tar.gz
spark-1.5.1-bin-hadoop2.6.tgz apache-storm-0.9.5.tar.gz
apache-flume-1.6.0-bin.tar.gz sqoop-1.4.6.tar.gz thrift-0.8.0.tar.gz
mongodb-linux-x86_64-rhel70-3.2.10.tgz redis-3.2.5.tar.gz
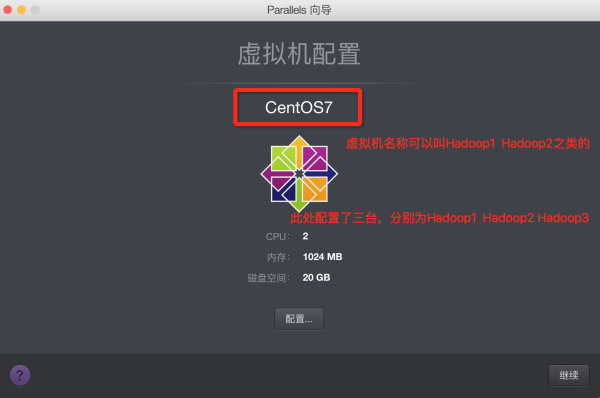
2.CentOS7 安装
PD这个软件在mac上算是特别好用的虚拟机了,用的当然是破解版的,目前有PD10的破解版,建议别升级,升级后不能用,也别将mac 升级成 mac sierra,升级后很多破解版的软件无法使用,吐槽一下苹果新版的MBP,那叫一个讽刺,自己的手机无法直接连接自己的电脑。
这里要往上选择一下第一个安装,这样不用检查,省去很多时间。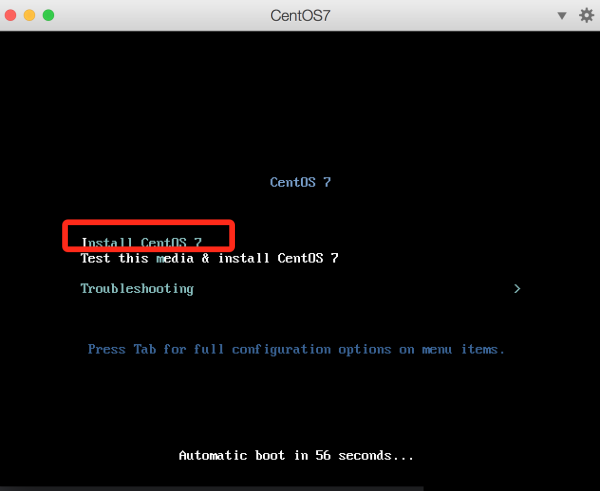
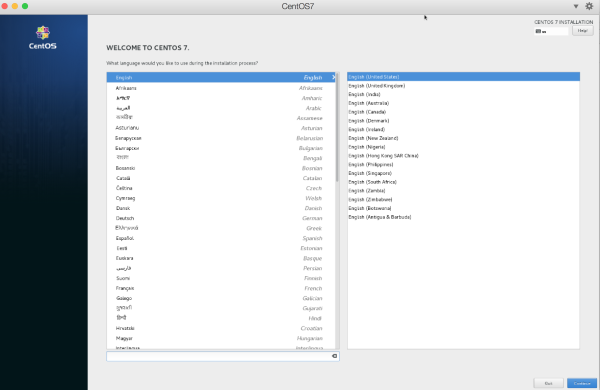
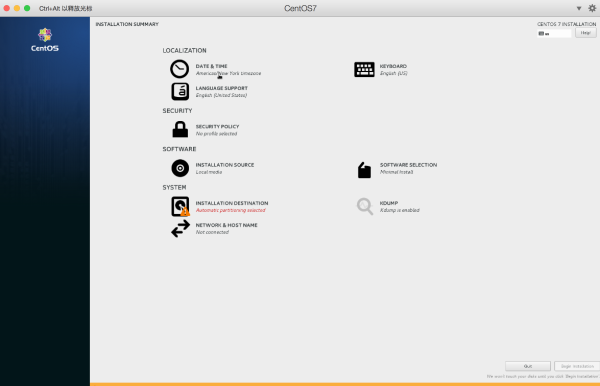
其中要设置一下时区,以及root的密码,以及一个用户及密码,这里所有的设置的用户为:hadoop,因为Hadoop环境建议不要直接用root用户直接去安装。这里有一点为分区的设置为题,就用默认的就行了。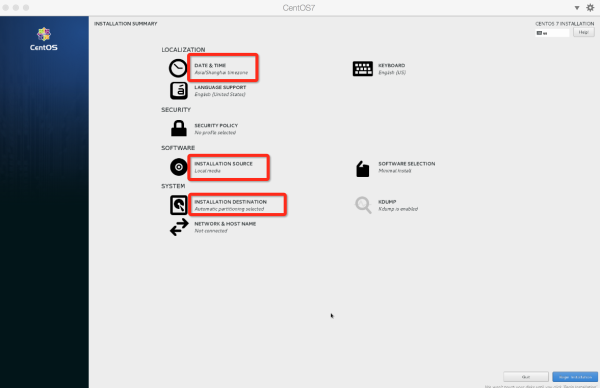
CentOS7安装有个好处为配置与安装分离,安装完基础的软件包后,再进行系统的配置。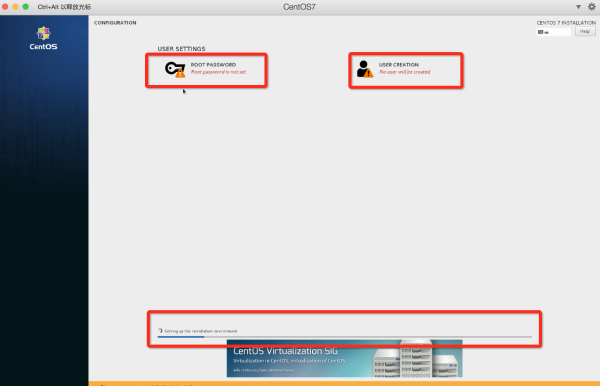
以上为CentOS7安装完毕,然后就可以重启登录了。第一次登录可用root用户登录并且设置。
(1).设置防火墙
在CentOS6.*的版本及以前,service iptables stop
在CentOS7中
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
即可,具体详细设置可看笔记CentOS7防火墙设置
(2).hostname设置
查看当前机器名:
hostname
默认为: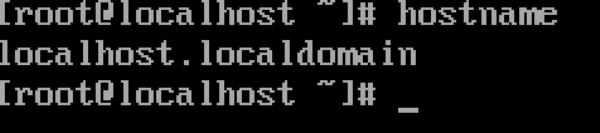
修改/etc/hostname文件
vi /etc/hostname
删除:localhost.localdomain
添加:Master.Hadoop
保存退出:wq
其他两台分别为:
Slave1.Hadoop
Slave2.Hadoop
(3).配置ip
CentOS6.*查看ip地址命令为:
ifconfig,CentOS7修改为:ip addr因为所用PD虚拟机的网络设置为共享网络,故只需要在eth0配置文件将开机启动设置为
yes即可,因每增加一台虚拟机,PD变会将ip进行自增,且下次开机不会改变。如果是物理机的话,就需要配置ip地址,相关的配置不做太多介绍,主要配置IPADDR``NETMASK``GATEWAY三个即可。vi /etc/sysconfig/network-scripts/ifcfg-eth0
将ONBOOT=no 变为 ONBOOT=yes
保存退出:wq
/etc/init.d/network restart 即可
此时,
ip addr即可查看相应的ip。本人搭建了三台虚拟机,其ip分别为:
10.211.55.13 Master.Hadoop
10.211.55.14 Slave1.Hadoop
10.211.55.15 Slave2.Hadoop
#### (4).hosts配置
hosts相关配置如下:
vi /etc/hosts
添加
10.211.55.13 Master.Hadoop
10.211.55.14 Slave1.Hadoop
10.211.55.15 Slave2.Hadoop
:wq
以上为CentOS7的安装及其配置,接下来为SSH无密码登录配置。
——————-
### 3.SSH无密码验证配置
默认安装好的系统上已经安装了ssh和rsync,可以通过以下命令查看:
rpm –qa | grep openssh
rpm –qa | grep rsync
如果提示没有安装,则需安装,如果安装跳过该步
yum install ssh #安装SSH协议
yum install rsync #rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件)
systemctl restart sshd.service #启动服务
这句话一定要看,一定要看,因为关系到配置ssh效率的问题。
原理说白了就是:需要将Master的公钥id_rsa.pub追加到所有的Slave的authorized_keys里边,将所有的Slave中的id_rsa.pub追加到Master的authorized_keys里边。
因此先配置Master和所有的Slave机器的sshd_config
vi /etc/ssh/sshd_config
将下边三个选项进行配置
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)
保存退出:wq,后要将sshd服务重启
systemctl restart sshd.service #启动服务
然后分别在所有机器的hadoop用户的~/目录下分别建立.ssh文件夹并将其权限设为700 chmod 700 .ssh
~/ 目录为登录hadoop用户后,直接cd下的目录
1).Master无密码登录所有的Slave
1.在Master上生成密码对
在Master节点上执行:
ssh-keygen -t rsa -P ‘’
这条命是生成其无密码密钥对,询问其保存路径时直接回车采用默认路径。生成的密钥对:id_rsa和id_rsa.pub,默认存储在”/home/hadoop/.ssh”目录下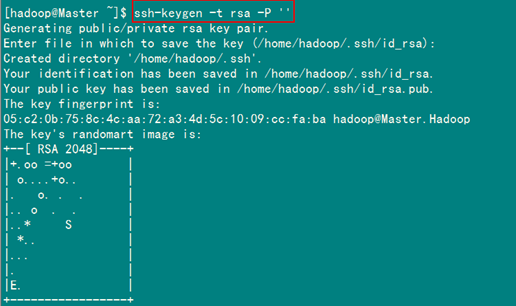
查看”/home/hadoop/“下是否有”.ssh”文件夹,且”.ssh”文件下是否有两个刚生产的无密码密钥对。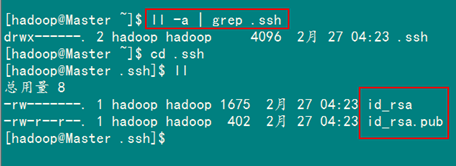
2.接着在Master节点上做如下配置,把id_rsa.pub追加到授权的key里面去。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

3.修改文件”authorized_keys”权限
权限的设置非常重要,因为不安全的设置安全设置,会让你不能使用RSA功能
chmod 600 ~/.ssh/authorized_keys
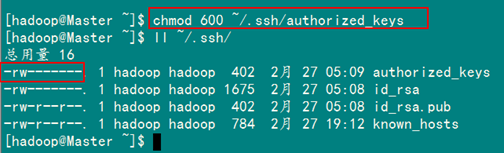
4.使用hadoop普通用户验证是否成功
ssh localhost
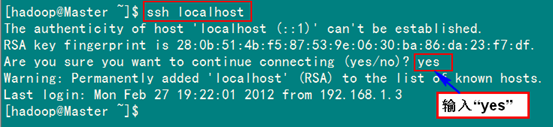
从上图中得知无密码登录本级已经设置完毕。
5.接下来是把公钥复制所有的Slave机器上,在下边的指令中,将公钥复制到了.ssh文件夹下,在初始状态下,Slave机器默认没有.ssh目录,Slave机器上没有创建的需要手动创建,已经有的忽略。使用下面的命令格式进行复制公钥:
scp ~/.ssh/id_rsa.pub 远程用户名@远程服务器IP:~/
例如:
scp ~/.ssh/id_rsa.pub hadoop@10.211.55.14:~/.ssh
scp ~/.ssh/id_rsa.pub hadoop@10.211.55.15:~/.ssh
然后分别登录Slave1和Slave2两台机器,将id_rsa.pub 追加到authorized_keys中,并将其权限设置为600后删除id_rsa.pub
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
rm ~/.ssh/id_rsa.pub
6.在Master上hadoop用户登录Slave上的Hadoop用户验证是否成功
ssh hadoop@10.211.55.14
ssh hadoop@10.211.55.15

不在提示让输入密码,表示Master登录所有Slave节点ssh配置成功。
2).Slave无密码登录所有的Master
和Master无密码登录所有Slave原理一样,就是把Slave的公钥追加到Master的”.ssh”文件夹下的”authorized_keys”中,记得是追加(>>)。
为了说明情况,我们现在就以”Slave1.Hadoop”无密码登录”Master.Hadoop”为例,进行一遍操作,也算是巩固一下前面所学知识,剩余的”Slave2.Hadoop”和”Slave3.Hadoop”就按照这个示例进行就可以了。
1.首先创建”Slave1.Hadoop”自己的公钥和私钥,并把自己的公钥追加到”authorized_keys”文件中。用到的命令如下:
ssh-keygen -t rsa -P ‘’
回车
回车
2.查看生成的公钥和私钥
cd
cd .ssh
ll
3.将公钥id_rsa.pub发送到Master
scp id_rsa.pub hadoop@10.211.55.13:~/
注意:这里发送到了~/目录下,没有到.ssh目录下,因为Master .ssh 目录下已经有一个id_rsa.pub,为Master之前生成的,因此不能将其替换。
4.登录到Master,将公钥追加到authorized_keys中,并修改其权限
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
rm ~/id_rsa.pub #追加完成后要删除id_rsa.pub
5.验证Slave无密码登录到Master
在Slave机器上
ssh hadoop@10.211.55.13
注:本人机器 55.13为Master 55.14为Slave1 55.15为Slave2
至此,SSH无密码通信已经配置完毕,我们可以发现一个规律,需要频繁登录Master和Slave上进行发送id_rsa.pub,为了简化,其实可以先将每一台的公钥生成,然后发送到Master中,发送的过程中可以起一个别的名字,别重名就行,然后在Master中统一将公钥追加到authorized key中。这样Master中算是有一份比较全的Slave key了,再将这一份发送到所有的Slave节点,变省去了很多发送的步骤。
如:
Slave1
scp ~/.ssh/id_rsa.pub hadoop@Master.Hadoop:~/.ssh/id_rsa1.pub
Slave2
scp ~/.ssh/id_rsa.pub hadoop@Master.Hadoop:~/.ssh/id_rsa2.pub
Master
cat ~/.ssh/id_rsa1.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/id_rsa2.pub >> ~/.ssh/authorized_keys
然后将authorized_keys 发送到所有的Slave
scp ~/.ssh/authorized_keys hadoop@Slave1.Hadoop:~/.ssh
scp ~/.ssh/authorized_keys hadoop@Slave2.Hadoop:~/.ssh
并确保Slave上的authorized_keys权限为600即可
本章结束,下一章,配置jdk以及hadoop。


